Data Warehouses คือ collection ของ data ที่เอาไว้ใช้สนับสนุนการตัดสินใจ โดย Data Warehouse ที่ว่านี้จะต้องเป็น:
- Subject Oriented ให้มองว่าปกติแล้วในระบบ Operation มันจะเป็น Application Oriented เช่น ระบบคลังสินค้า มันก็จะว่าด้วยเรื่องของการซื้อสินค้าเข้าคลัง ย้ายสินค้าออกคลัง, ส่วนระบบจัดซื้อก็จะว่าด้วยเรื่องที่ว่าเราจัดซื้ออะไรบ้าง แต่ว่าในแต่ละระบบมันก็จะมี data เฉพาะของมันเอง แต่ถ้าในเรื่องของ data warehouse แล้วเราจะไม่ได้มองเป็น application ใดๆแบบที่ได้กล่าวมา แต่เราจะมองว่า ข้อมูลที่เรามีอยู่แล้ว เราจะเอาไปวิเคราะห์เพื่ออะไร เช่นวิเคราะห์ผลกำไรขององค์กร เป็นต้น ดังนั้นข้อมูลที่จะอยู่ใน warehouses ของเรา มันจะต้องเป็นข้อมูลที่ดึงมาจาก application ต่างๆเอามารวมกัน ซึ่งถ้าเป็นแบบนั้นแล้ว เราจะไม่ออกแบบข้อมูลเป็น application oriented แต่เราจะออกแบบข้อมูลเป็น subject oriented ซึ่งคำว่า subject oriented ในที่นี้ก็คือว่า เป้าหมายของเราอยู่ที่ไหน เราก็จะออกแบบข้อมูลเพื่อไปตอบเป้าหมายของเราที่อยู่ตรงนั้น เราไม่ได้ออกแบบข้อมูลตาม application ในขณะที่ database ทั่วๆไปมันจะออกแบบโครงสร้างข้อมูลตาม application นั้นๆ และแน่นอนข้อมูลที่เราเอามาเก็บใน data warehouses ก็มักจะเป็นข้อมูลที่ถูกดึงมาจากหลายๆ application และเมื่อข้อมูลมาจากหลายๆแหล่ง ข้อมูลก็มักจะต้องมีความขัดแย้งกัน และข้อมูลที่ถูกดึงเข้ามาก็มักจะมีข้อมูลเกี่ยวกับเวลาเข้ามาเกี่ยวข้องด้วย (จริงๆข้อมูลจะมีเวลากำกับอยู่เสมอ) เนื่องจากเป็นการเก็บข้อมูลแบบพอกพูนเพิ่มขึ้นเรื่อยๆ ไม่ได้ลบทิ้งออกไป
- Non-Volatile Data เราจะไม่ได้ลบข้อมูลเก่าออกไป ดังนั้นข้อมูลมันจะไม่มีวันสูญหาย (โดย concept)
–
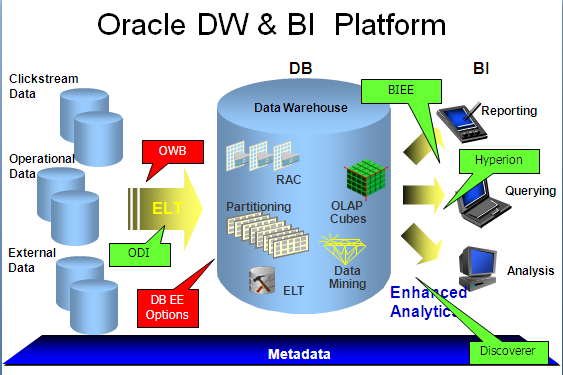
Data Warehouse VS Traditional Database
ในที่นี้ เราจะมองในเรื่องของลักษณะข้อมูล การโปรเซส ลักษณะการใช้งาน และการออกแบบ
Data warehouse
- Subject-Oriented
- เป็นข้อมูลที่เก็บสะสมไปเรื่อยๆ แต่โดยมากแล้ว ยังไม่ได้เก็บข้อมูลของปัจจุบันยัง ณ ตอนนั้นโดยทันที แต่จะรอจนกว่าจะถูกสั่งให้ดึงข้อมูลเข้ามา
- ข้อมูลเป็น static มีแต่ข้อมูลใหม่เพิ่มเข้ามา ข้อมูลเดิมไม่มีการเปลี่ยนแปลง
- Transaction จะเป็นแบบการดึงข้อมูลเป็นจำนวนมาก และเอามาวิเคราะห์แบบซับซ้อน และเรามักจะไม่รู้ว่าวันนี้เราจะวิเคราะห์อะไร (แล้วแต่ผู้บริหารว่าอยากจะรู้อะไร) เวลาจะวิเคราะห์แต่ละครั้ง ปกติมันก็ต้องไปยุ่งกับข้อมูลจำนวนมาก ทำให้เราพยายามหลีกเลี่ยงไม่ให้เกิดการ Join ตารางกัน และพยายามจะไม่ normalize มัน โดยสิ่งที่เราจะมองหลักๆคือ เราจะทำยังไงให้มันดึงข้อมูลออกมาได้ง่าย และเร็ว
- มีเพียงไม่กี่คนที่เข้ามาใช้ แต่ว่าแต่ละครั้งที่ใช้จะ take processing power จำนวนมาก
Traditional Database
- Application-Oriented
- ข้อมูลปัจจุบันในฐานข้อมูล จะเปลี่ยนแปลงเรื่อยๆ
- Transaction จะเป็นแบบสั้นๆ ง่ายๆ ซ้ำๆ และเกิดบ่อยๆโดยการอ่านไม่กี่ record ในฐานข้อมูล
- ปกติจะมีคนใช้เยอะ และกิน processing น้อย
เนื่องจาก 2 แบบที่กล่าวมานี้ จะเห็นว่าลักษณะการใช้งานแตกต่างกัน ทำให้เราต้อง configure database ต่างกัน รวมทั้งการออกแบบ database ก็จะต่างกันด้วย
–
Problem in Building Data Warehouses
ปัญหาที่เห็นชัดๆเลยก็คือในเรื่องของ Data homogenization: บางที เราเอาข้อมูลที่มีธรรมชาติต่างๆกัน จากหลายๆแหล่งมารวมกัน บางทีมันรวมกันลำบาก และเพื่อให้มันรวมกันได้ เราจำเป็นต้องตัดส่วนที่มันต่างกันออกไป ทำให้เราเสียความเป็นความเฉพาะเจาะจงของข้อมูลออกไป มันก็เลยเป็นปัญหาว่า ถ้าเราอยากจะวิเคราะห์ข้อมูลข้ามหลายๆเรื่อง บางทีทำให้เราต้องตัดรายละเอียดออกไปบ้าง เพื่อให้ข้อมูลสามารถเข้ากันได้ เช่นเราเอาข้อมูลจากหลายๆแหล่งมาลงในตารางเดียวกัน บางทีมันทำไม่ได้ เพราะ attribute มันไม่เหมือนกันจะลงตารางเดียวกันได้ไง ทำให้เราต้องตัดให้เหลืิอส่วนที่มันเหมือนกันเท่านั้น ถึงจะเอามาลงตารางเดียวกันได้
ตอนต่อไปจะว่าด้วย Components ต่างๆของ Data warehouse


 )
)