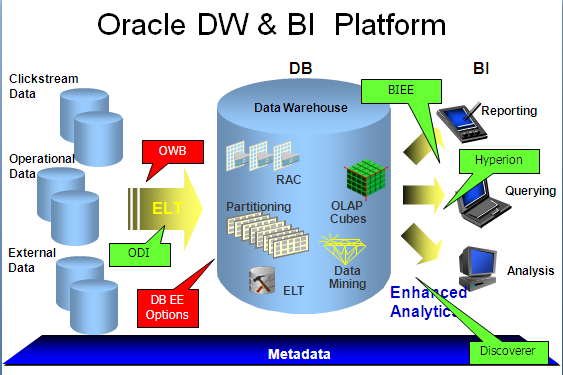
Data Warehouse
ต่อจากตอนที่แล้วที่เป็นเรื่องเกี่ยวกับ Architecture ของ Data Warehouse และ component ต่างๆที่เราควรรู้จักไว้ ซึ่งส่วนที่สำคัญอีกส่วนหนึ่ง ที่จะนำข้อมูลเข้ามาเก็บไว้ใน Data Warehouse ก็คือ ETL Tools ซึ่ง ETL Tools เป็นสิ่งที่ทำให้เราไปดึงข้อมูลเข้ามาได้ง่ายๆ ซึ่งถ้าเราไม่มี ETL Tools เราก็คงต้องเขียน select … from… where… เพื่อดึงข้อมูลเข้ามาเก็บเองด้วยมือเปล่า หรือบางที source ก็อาจไม่ได้เป็น Database ทำให้เราเขียน SQL ไปดึงข้อมูลมาไม่ได้
ETL Tools มีความฉลาดที่จะรู้จักข้อมูลชนิดต่างๆ แต่ทั้งนี้ทั้งนั้นก็ขึ้นอยู่กับว่าเราซื้อ ETL Tools ของใคร โดยแต่ละยี่ห้อก็จะมีความสามารถต่างๆกันไป เช่น ถ้าเราซื้อ ETL Tools ของ Oracle แล้ว ETL Tools ตัวนั้นก็อาจเป็นไปได้ว่าจะติดต่อ และเข้ากันได้กับ Oracle ได้มากกว่า ETL Tools จากค่ายอื่นๆ เป็นต้น
-
Extract-Transform-Load Process
โดยทั่วไปแล้ว ETL Tools ทำอะไรบ้าง?
Data Cleansing - เมื่อมีข้อมูลมาแล้ว เราจะต้องมีการตรวจสอบความถูกต้องของข้อมูล แล้วปรับให้มันดีขึ้น รวมทั้งกำจัดข้อมูลทีผิดพลาดไป (ก็แล้วแต่ราคา และยี่ห้อของ ETL Tools ไม่ใช่ว่าทุกๆตัวทำได้เหมือนๆกัน)
Data Transformation - ข้อมูลบางอย่างที่เราได้มามันไม่ได้อยู่ในรูปแบบที่เราจะเอาไปวิเคราะห์ได้ ง่ายๆ เช่น เรามีข้อมูลของคน เช่นวันเดือนปีเกิด ของลูกค้า แล้วเวลาเราเอาไปวิเคราะห์เราไม่ได้เฉพาะเจาะจงเป็นวัน เราจะคำนวนเป็นช่วงอายุ เช่นวัยเด็ก ผู้ใหญ่ ชรา เป็นต้น ทำให้เราต้อง convert ก่อนว่าเป็นวัยไหน เป็นต้น แต่ว่ายังไงก็ตามบางทีเราไม่ได้ใช้ค่าจริงๆของมันหรอก เราจะใช้ค่าเชิงหมวดหมู่ของมันเป็นต้น ตรงนี้เป็นหน้าที่ของ data transformation ซึ่งถ้ามี ETL Tools ดีๆเราสามารถกำหนดเงื่อนไขในการแปลงให้ได้เลย
Data Loading and Refreshing - กำหนด schedule ได้ว่าจะให้โหลดมาทุกๆกี่วัน หรือทุกๆเท่าไหร่ รวมทั้งยังสามารถกำหนด storage ปลายทางได้อีกด้วย
-
Data Warehouses
multi-dimensional เก็บข้อมูลหลายๆ dimension ก็เช่น สรุปยอดขายตามสินค้าที่ขาย ตามเวลาที่ขาย ตามสาขาที่ขาย เป็นต้น
multi-level ก็เช่นเราอยากรู้เป็นตัวๆ ว่าขายอะไรไปเท่าไหร่ หรืออาจจะอยากรู้เป็นกลุ่มๆก็ได้ว่าสินค้ากลุ่มนี้ขายได้เท่าไหร่ หรืออาจจะดูเป็นระดับสาขา ระดับภาค หรือระดับประเทศก็แล้วแต่ว่าจะเลืิอก level แบบไหนยังไง
-
Approach to Building Data Warehouse Systems
แบ่งเป็น 2 แนวทางใหญ่ๆคือ Top-Down และ Bottom-Up
Top-Down เรามองว่าองค์กรของเราต้องการสร้าง data warehouse เราก็ออกแบบมาเป็นอันใหญ่เลย พอออกแบบเสร็จแล้ว แต่ละหน่วยงานอยากจะเอาไปวิเคราะห์ก็จะดึงจาก warehouses อันใหญ่ไปวิเคราะห์ เอาไปเก็บไว้กับตัวเอง เช่นฝ่ายขายดึงไปวิเคราะห์ เราเรียกตรงนี้ว่าเป็น Data Mart ของฝ่ายขาย แล้วเวลาจะเอาไปวิเคราะห์ก็จะมี OLAP ของฝ่ายขายเองเข้าไปดึงจาก warehouse แล้วก็ใช้ OLAP ของเค้าวิเคราะห์เอาเอง หรือเค้าอาจจะไม่สร้าง Data Mart แต่โหลดไปทำ OLAP เลยก็ได้เหมือนกัน การออกแบบในลักษณะนี้ก็อาจจะทำให้ warehouses หลักทำงานเหนื่อยเกินไป เพราะว่าใครๆจะใช้อะไรก็ต้องมาต่อตรงที่นี่ทุกที
การทำแบบนี้โอกาสประสบความสำเร็จ มันค่อนข้างต่ำ เพราะถ้าเราจะทำระบบใหญ่ๆ แล้วถ้าหากว่าเราไม่รู้ครบถ้วนทุกแง่มุม บางทีมันไม่เสร็จสักที หรือไม่ได้เริ่มซักที ทำตรงไหนก็ผิดไปหมด แต่ถ้าหากว่าเราทำได้ดี มันก็จะได้ผลลัพธ์ที่ดี เพราะเราออกแบบมาตั้งแต่แรกหมดแล้ว
Bottom-Up คือเอาภาคย่อยๆของหลายๆอันมารวมกัน (เอา data mart หลายๆอันมารวมกัน) แต่ก็อาจจะมีปัญหาคือ แต่ละอันก็จะมีการออกแบบที่ต่างกันไป อาจจะใช้ระบบวิธีการสร้าง ID อะไรกันไม่เหมือนกัน รอบของการอัพเดทข้อมูลก็อาจะไม่ตรงกัน แต่ละคนคิดไม่เหมือนกัน ทำให้เวลาเอาไปสรุปก็อาจจะเกิดปัญหาอีกได้ ดังนั้นการที่เราออกแบบไว้หลายๆอันแล้วเอามารวมกันอาจจะยุ่ง ทำให้เราต้องปรับแก้อะไรบางอย่างก่อนเอามารวมกัน ทำให้การออกแบบแบบนี้ อาจจะไม่ใช่วิธีการที่ดีเท่าไหร่นัก
แต่ก็แล้วแต่ว่าใครจะใช้แบบไหน ขึ้นอยู่กับประสบการณ์ ซึ่งประสบการณ์ที่ว่านั้น รวมไปถึงประสบการณ์ทั้งการทำ data warehouses และประสบการณ์ทั้งทาง domain หรือเรื่องที่จะทำนั้นๆด้วย
ตอนต่อไปเราจะมาพูดถึงเรื่อง Data Warehouse Model และ Schema บ้าง


 )
)